
Machine Learning, Business Intelligence, and Artificial Intelligence are buzz words that are being thrown around at planning sessions a lot these last few years. They have real meanings that most people don’t understand. They are using them to mean “more sophisticated at using data to make decisions”. And while that is right, there is a right way and a very wrong way to lead your company down the path of using data to make data-driven decisions. After 10+ years of helping companies understand what that path is, we wanted to help you the reader understand the order and the real definitions of the buzz words. This way, you can not be educated, but you can give your company the direction it needs to go up the Data Hierarchy.
Data Science is in an integral part of everyday life at this point and you just don’t know it. As a society, we’re generating more data than ever before. Smart businesses are tapping into that data to do things that were previously unheard of.
Take Facebook for example. 20 years ago Facebook didn’t exist, now people are addicted to it and seemingly can’t live without it. But even then, people are still weary of the dreaded “Facebook algorithm” that cuts 50% of the posts you might want to see. That algorithm is data science at work

That’s right, you’ve generated enough data that Facebook wrote some code to cut 50% of your friends out of your life. You didn’t interact with them enough, they didn’t post enough, there are hundreds of reasons why that system feels like your college roommates buddy from down the hall with the cat doesn’t need to be at the top of your feed. It also looks at what you read on a regular basis and then tries to predict what you would want to read next.
So to help people truly understand what we do as a company, and to help you hire us. (let’s be honest) We put together a series on the sophistication of data usage as businesses mature that we call the Business Data Hierarchy. The goal of this series is to help people and companies understand where they are now, and where they could go with data driven decision making.
We’ve written the series to be informative and insightful, with a splash of humor mixed in to keep you awake through the whole process. If you like it or if you feel like someone needs to read this…we ask that you share the info or…better yet…get them in touch with us and we’ll bring the show to you! The pyrotechnic guys tell us we’ll need a 25’ ceiling for the fire and lasers…Hey, it’s a good show.
…this will also be the longest post of the entire series, don’t worry!

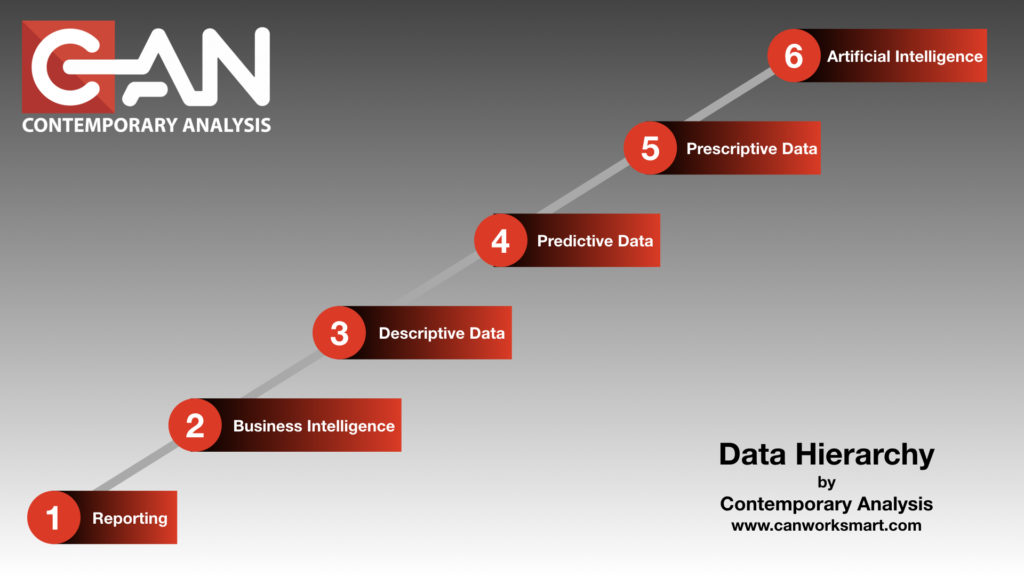
When you look at Data, and what it can do for you and your company, there are six different levels of Data Hierarchy. It’s a hierarchy because each level is codependent on another.
These levels are important to understand because jumping from one to another, without a long term goal, can be cost prohibitive. This is even more devastating when you finally get your executive level to believe in the power of data, and it breaks the bank in the execution.

There are consultants with lovely summer and winter homes who have paid for them “skipping” to the end and then back billing/building the solutions.
To insulate against catastrophic failure of a data-driven initiative we at Contemporary Analysis (CAN) have created a Data Hierarchy to help companies understand where they are and more importantly, where they are going. This understanding helps drive the strategy and vision needed to be successful. These levels are
- Reporting: Tracking and “What happened?”
- Business Intelligence: “What just happened?”
- Descriptive Data: “Why did that happen?”
- Predictive Data: “What is going to happen next?”
- Prescriptive Data: “What should we do to make it happen?”
- Artificial Intelligence: “Automated recommendations”
- Omnipotent AI (Skynet): “Automated Doing of its own recommendations” a.k.a. “Terminator Movies”
Every business is trying to move “forward”. If you work for a company whose response is anything but “forward” or “more” start polishing up your resume, you’ll need it sooner than later.
Most companies are so focused on today’s business they don’t know what the path to the future looks like.
Imagine you tell a CEO you’re going to walk a mile to get another 1 million in sales. Most CEO’s would look at the distance and agree that a short distance is worth the time and effort to get the additional revenue.

You and your team(s) work feverishly to get from point A to point B as quickly as possible. You cross the finish line and there’s your 1 million. The CEO checks the box and there it is, project complete.
Now imagine if you told a CEO you’re going to get 20 million in sales. After the confused look and possible laughing subsides you tell them how. Instead of a mile, you have to walk 15 miles. But you’re not going to do them all in 1 year. Instead you’re going to walk that distance over 5-6 years. You’ll measure success with each mile you pass and each mile will result in ROI for the company.

You also let them know that you can cover the ground when and how you want to. If one mile is too tough to work in the time and effort this year, you postpone it to the next. If, as you’re walking, a business need changes and you need to walk a completely different direction you can. The steps remain the same but the road you use to get there is slightly different.
Understanding the long term goal allows you and your team(s) the ability to work smarter not harder. You’re building toward the vision at every turn so you have little to no wasted effort. And, because you’re building over time, you can staff accordingly for each mile and access the right talent at the right time
Part of CAN’s role is being that “Data Visionary” that helps you see over the horizon with possibilities. The hardest part of this whole process is getting the decision makers in an organization to embrace the culture of change.
“We’ve done it this way for __X__ years and it works just fine.” Is becoming the leading indicator of a dying business. If you’re 40 years old the technology available today wasn’t even conceptualized when you were in grade school. “We’ve done it this way for 50 years…” means you’re already behind the curve.
The posts that will follow will walk you through each level of the Business Data Hierarchy concept. We’ll be sure to include examples that are relatable. The subject matter can be a bit dry, so we’ll also make sure we include some humor along the way to keep things lively. We’re a Data Science Consulting firm..not monsters after all.
At any point, feel free to reach out and let us know how we can help you through these steps:
Reporting
Business Intelligence
Descriptive Analytics
Predictive Analtyics
Prescriptive Analtyics
Machine Learning
Artificial Intelligence






