Contemporary Analysis (CAN) is pleased to announce and welcome Justin...
Contemporary Analysis Welcomes our new Business Development Officer
read more
Contemporary Analysis (CAN) is pleased to announce and welcome Justin...
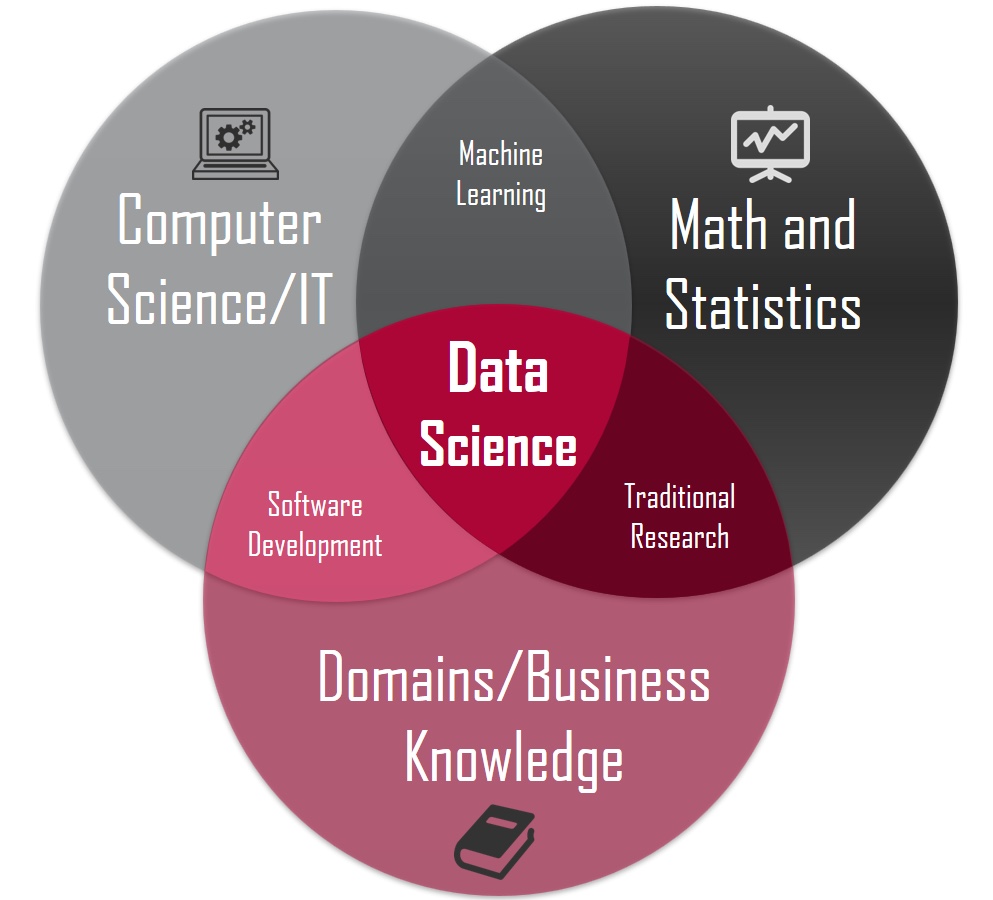
We are excited to announce a partnership with Bellevue University, the beginnings of...
LinkedIn released their August workforce report today which revealed that the...
Last Thursday, Data Science on the Plains hosted their first meetup event. The event...
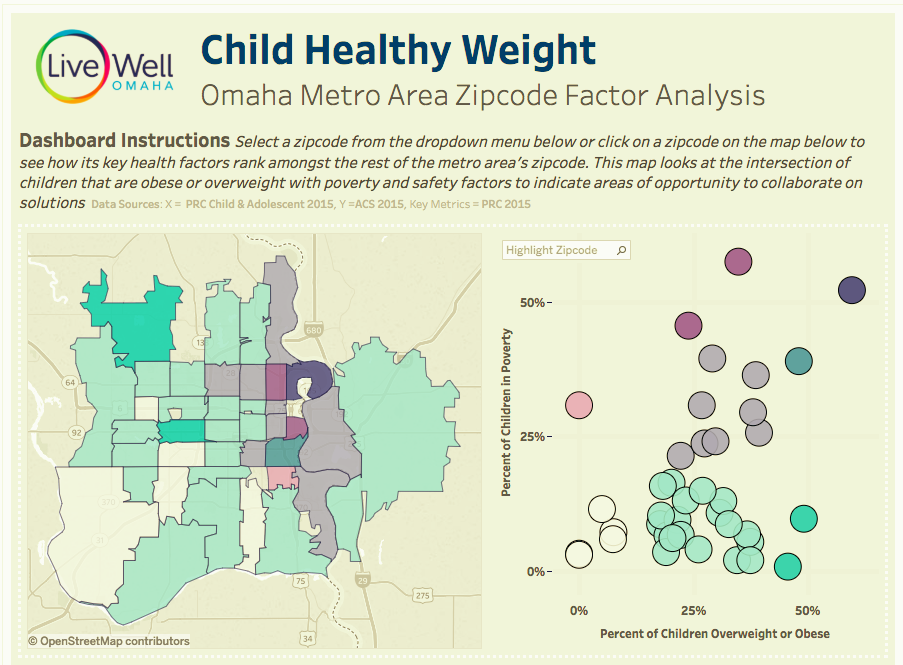
Live Well Omaha is a nonprofit that leads a coalition of organizations to collectively...
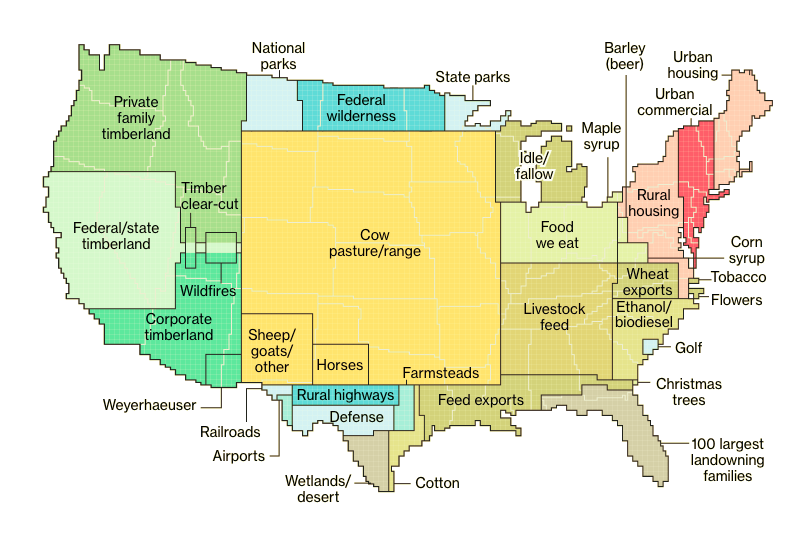
Here at Contemporary Analysis, we believe good data visualization is the key to...
Data science has been named America’s hottest job by an article written in Bloomberg. In...

The GI Bill is now accepted by the Omaha Data Science Academy. Veterans, in partnership...
Your Data Isn't Ready, and Your Company Might Not Be Either As of May 25th, all...