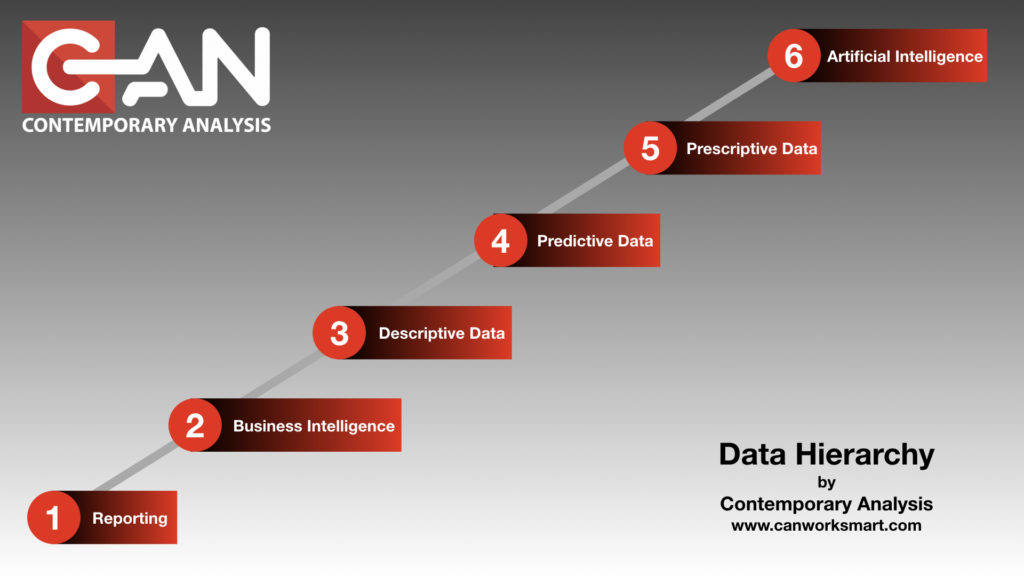
Well if you made it to Wordcamp Omaha or Heartland Developers Conference you may have seen our Data Hierarchy Series presentation.
To help set the tone and to have a little fun, we hired Gilbert Gottfried to do what he does best…rant and rave. Using our extensive network of resources and hunting down lead after lead after lead to get to him we hired him to do our intro. (100% made up…it was super easy to hire him…and for WAY less than anyone here though it would be!)
Here is the video in its entirety:
Leave a comment below with how much you think it cost to hire him. The actual answer may surprise you!